Git Yo'self Some Data
How we can (and can't) use open source tooling for open data
James Smith · @floppy
WTF is the
Open Data Institute?
- non-profit, non-partisan
- founded 2012 by Tim Berners-Lee and Nigel Shadbolt
- "helping others be successful with open data"
- economic, social and environmental value
WTF is
open data?
Open data is information that is available for anyone to use, for any purpose,— http://theodi.org/guide/what-open-data
at no cost.
- open data
must have have a licence to say it is open - the license
may impose some constraints:
attribution and/or share-alike
A piece of data or content is open if anyone is free to use, reuse, and redistribute it — subject only, at most, to the requirement to attribute and/or share-alike.— http://opendefinition.org/
So What?

Data you can get
!= Open Data
- Twitter Firehose
- Google Maps
- ... and most others
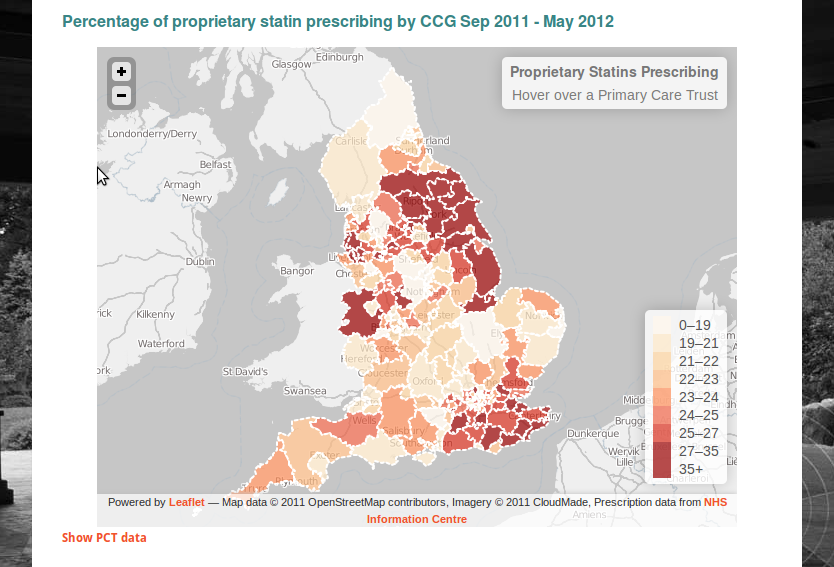
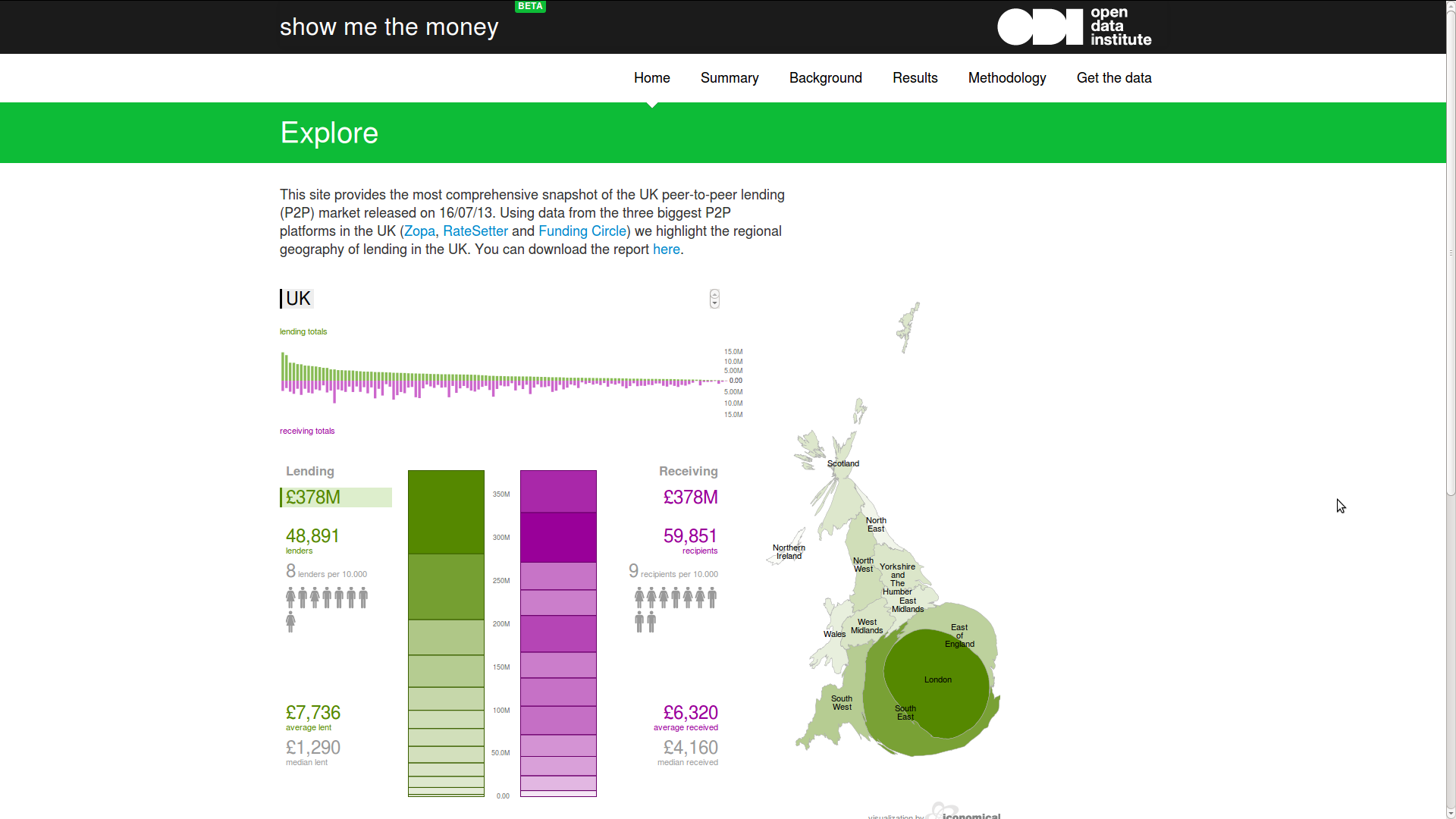
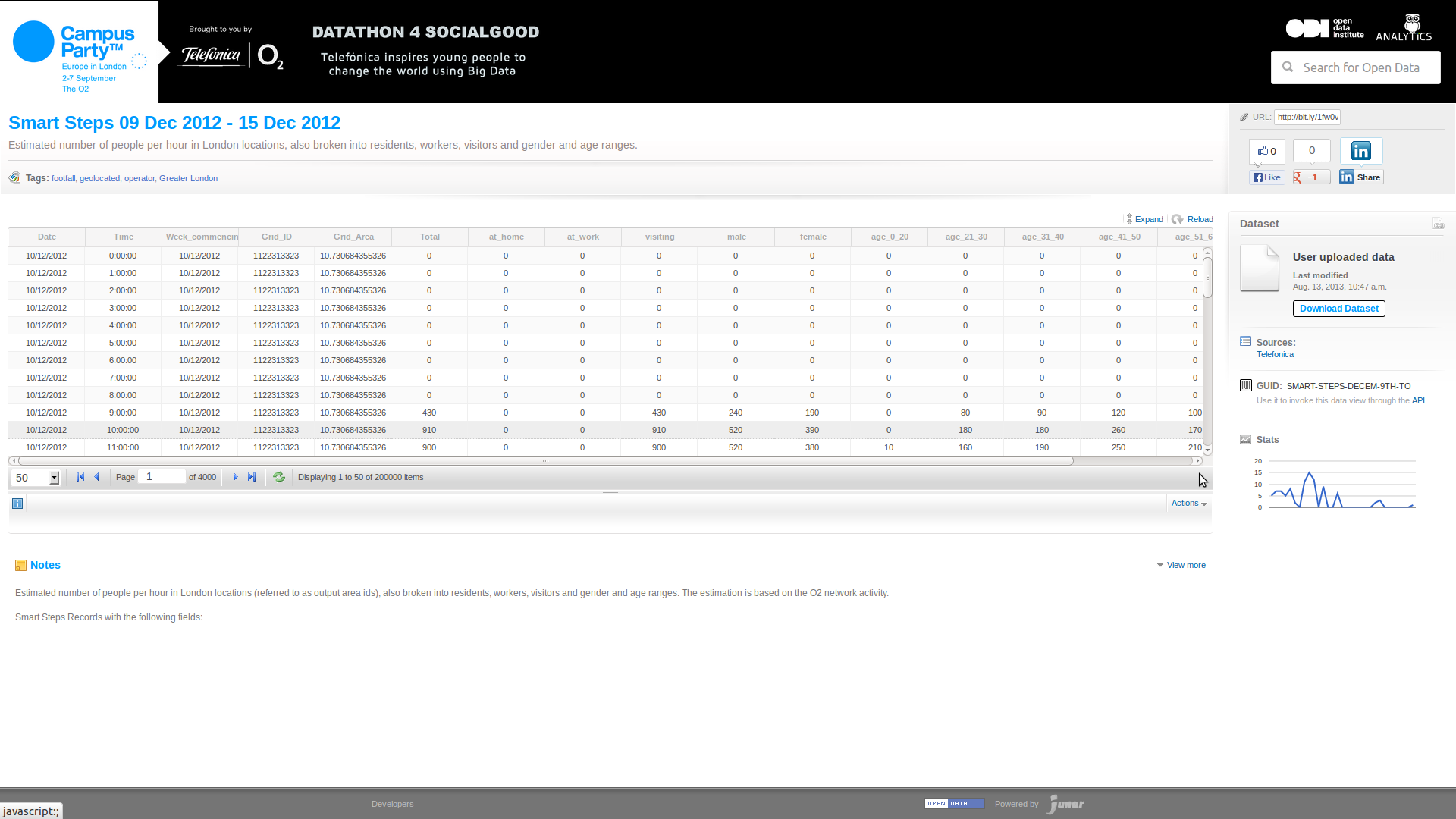
Good Open Data
- can be linked to
so that it can be easily shared and talked about - is available in a standard, structured format
so that it can be easily processed - has guaranteed availability and consistency over time
so that others can rely on it - is traceable, through any processing
so others can work out whether to trust it
Open Data Certificates
Data Collaboration

Image from MindJet
I ♥ Open Source!

Not Octocat by Cameron McEfee
GitHub Flow
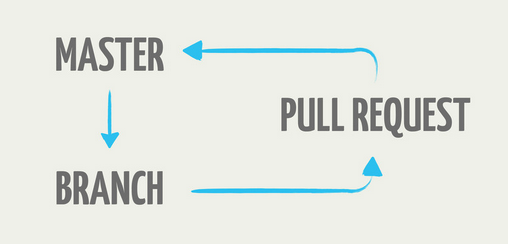
from How Github uses GitHub to build GitHub by Zach Holman
SourceForge.net (in 2000)
GitHub ALL the things!
> %w{teachers accountants governments dogs cats hamsters DATA}.each do |x|
> puts "GitHub for #{x}!"
> end
GitHub for teachers!
GitHub for accountants!
GitHub for governments!
GitHub for dogs!
GitHub for cats!
GitHub for hamsters!
GitHub for DATA!

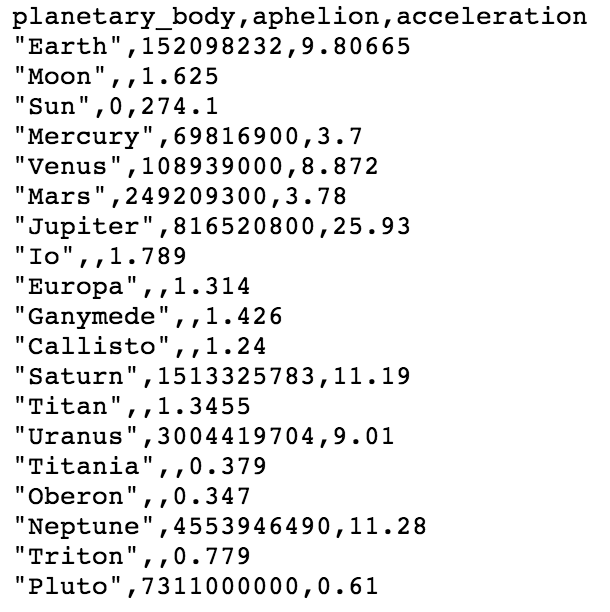
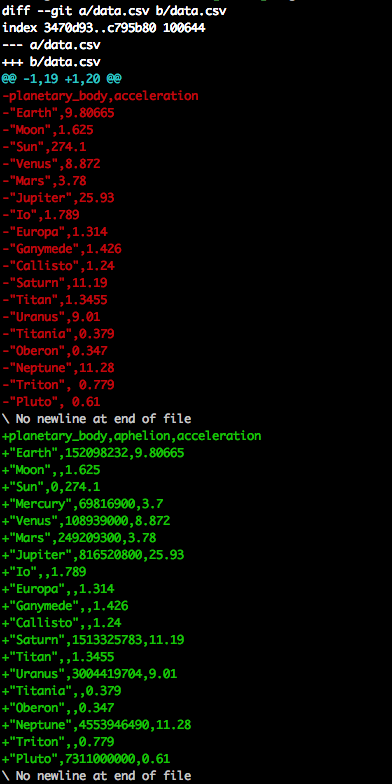
er...
Git CLI
git diff --word-diff- ~/.config/git/attributes
*.csv diff=csv - ~/.gitconfig
[color] ui = true [alias] diffcsv = diff --word-diff [diff "csv"] wordRegex = ...?
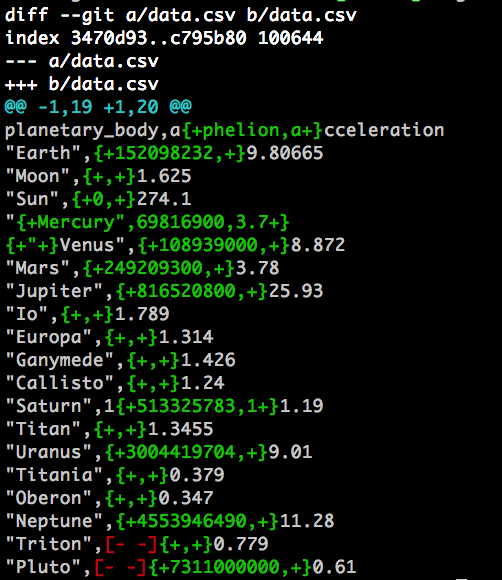
wordRegex=.
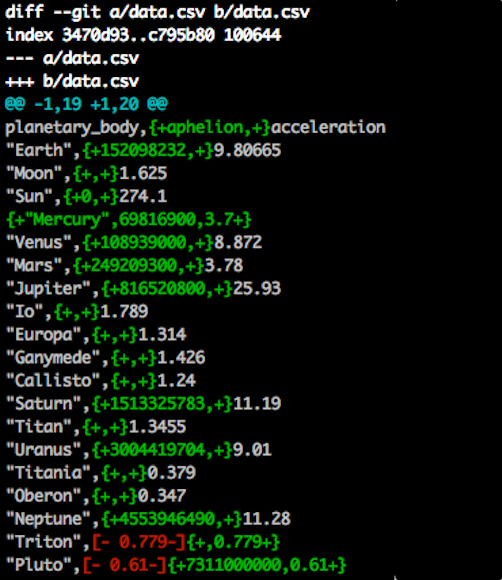
wordRegex=[^,\n]+[,\n]|[,]
csv-my-git
Automatically configure your local git installation for CSV
curl -L http://theodi.github.io/csv-my-git/install.sh | bash
git diffcsv test.csvGitlab
Open Source GitHub-alike
![]()
File & diff views
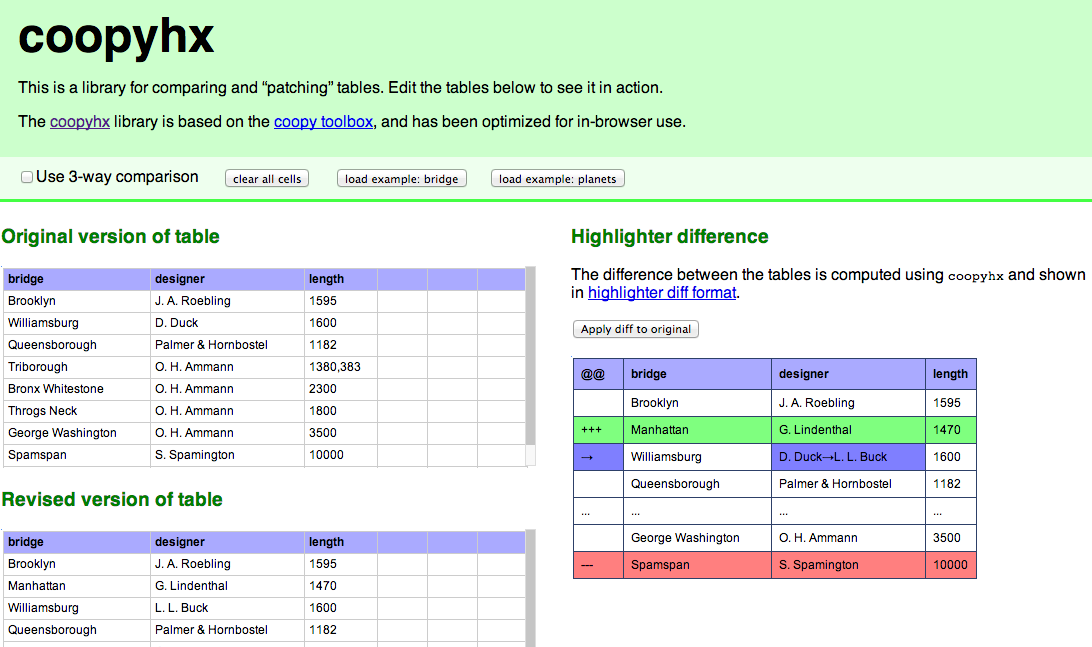
http://paulfitz.github.io/coopyhx/
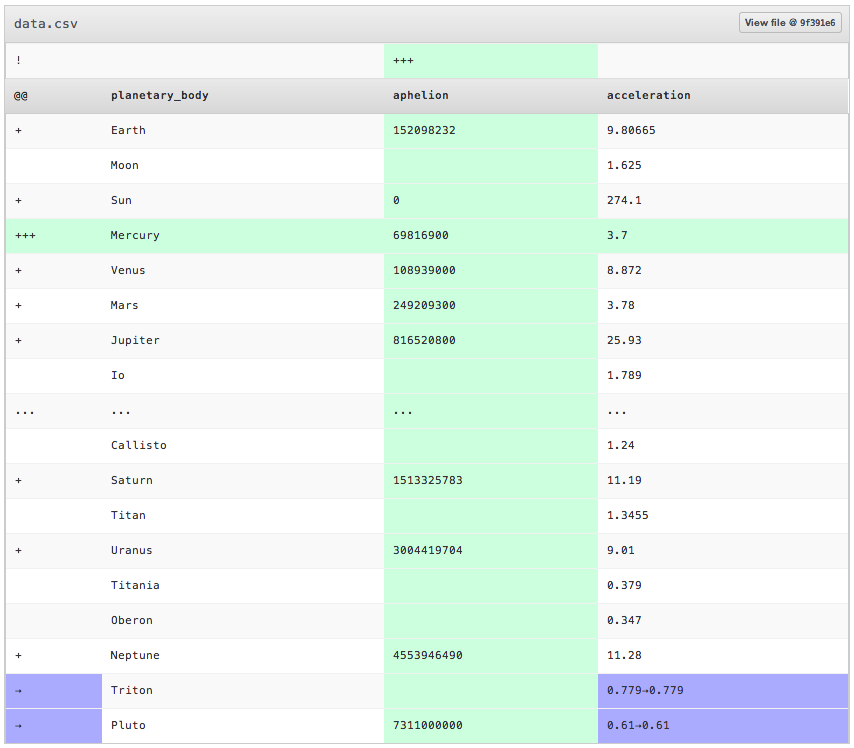
GitHub
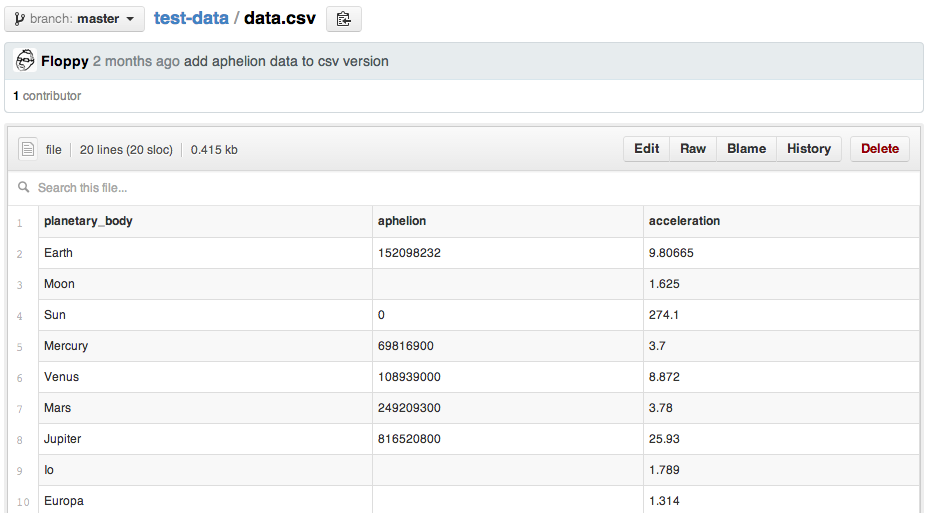
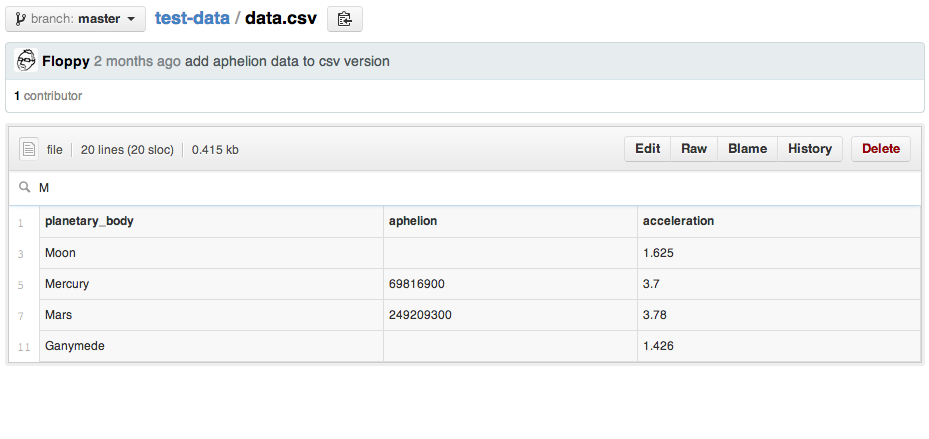
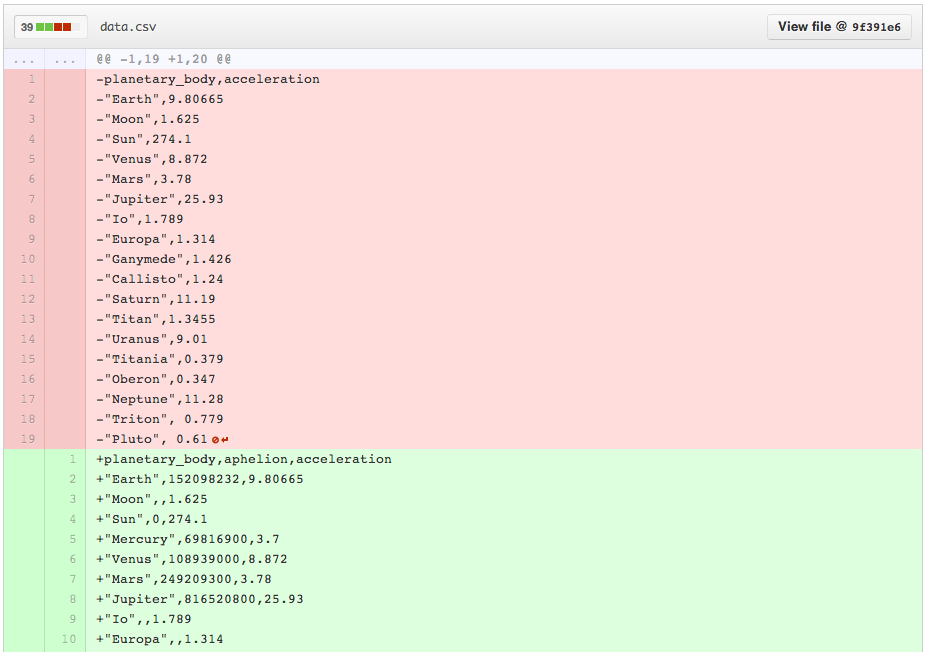
Winning!
Standards
(de facto or otherwise)

http://dataprotocols.org
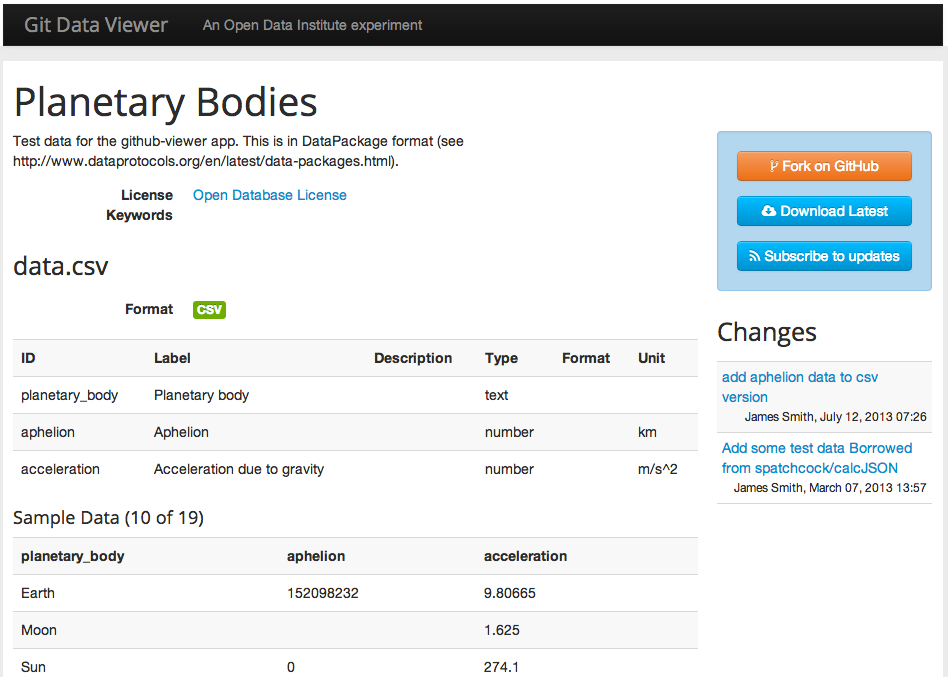
Data Kitten

https://github.com/theodi/data_kitten
Data Ecosystem
- Dependency Tracking
- Validation & Testing
- Quality Metrics
- Visualisation
- Conversion & Decoration
Crowdsourcing!
https://github.com/benbalter/github-forms
https://github.com/datasets
https://github.com/Chicago

http://sfmoci.github.io/openlaw/
ZOMG GIT FIXES EVERYTHING
Limitations
Adding a large file (50m lines)
13m 40s
Changing a single line
8m 30s
figures by Max OgdenDat
# make a new dat store
dat init
# put a JSON object into dat
echo '{"hello": "world"}' | dat
# stream the most recent of all rows
dat cat
# pipe dat into itself (increments revisions)
dat cat | dat
# start a dat server
dat serve
# delete the dat folder (removes all data + history)
rm -rf .dat
R&Wbase
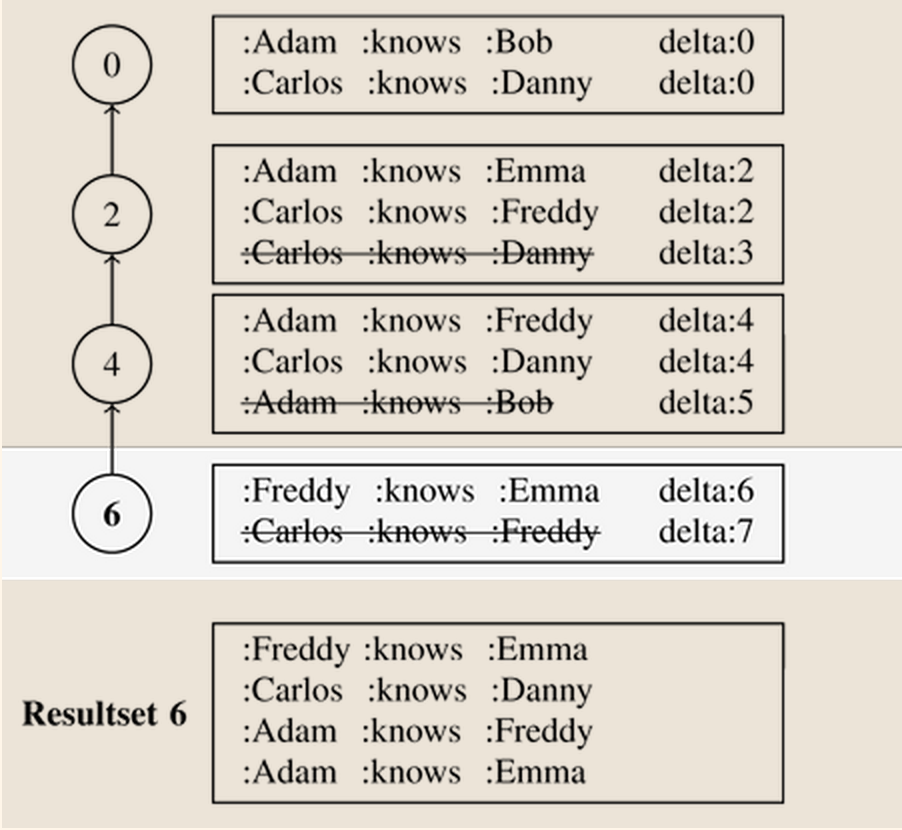
http://rawbase.github.io/
Where Next?
- Server-side diff calculation
- Merging
- Conflict resolution
- CSV dialect support
- More tools!
Contribute!
- ODI blog post:
- Gitlab fork:
- Git CLI configurator:



